![[논문 리뷰] Security and Privacy Challenges of LLM: A survey](/content/images/size/w1200/2026/03/----------------3.png)
논문: Security and Privacy Challenges of LLM: A Survey
Badhan Chandra Das, M. Hadi Amini, Yanzhao Wu — Florida International University
리뷰 계기: 김태호 교수님 연구실 논문 리뷰 세션

ChatGPT를 비롯한 LLM이 금융, 의료, 교육 등 실제 산업 영역에 빠르게 침투하면서 자연스럽게 따라오는 질문이 있다. 이게 얼마나 안전한가? 이 논문은 그 질문에 체계적으로 답하려는 서베이 페이퍼다. 공격 기법, 프라이버시 위협, 방어 메커니즘, 그리고 현재 연구의 한계까지 전반적으로 정리되어 있어서 LLM 보안 입문 자료로도 좋았다.


LLM은 어떻게 동작하는가?
공격 기법을 논하기 전에, LLM이 어떻게 출력을 생성하는지 기본을 짚고 가는 게 좋다. 사용자 쿼리가 들어오면 입력은 임베딩 벡터로 변환되고, 여러 Transformer 레이어를 거쳐 각 토큰에 대한 확률 분포를 계산한다. 그중 가장 높은 확률의 토큰을 선택하고, 종료 조건을 만족할 때까지 이 과정을 반복한다.
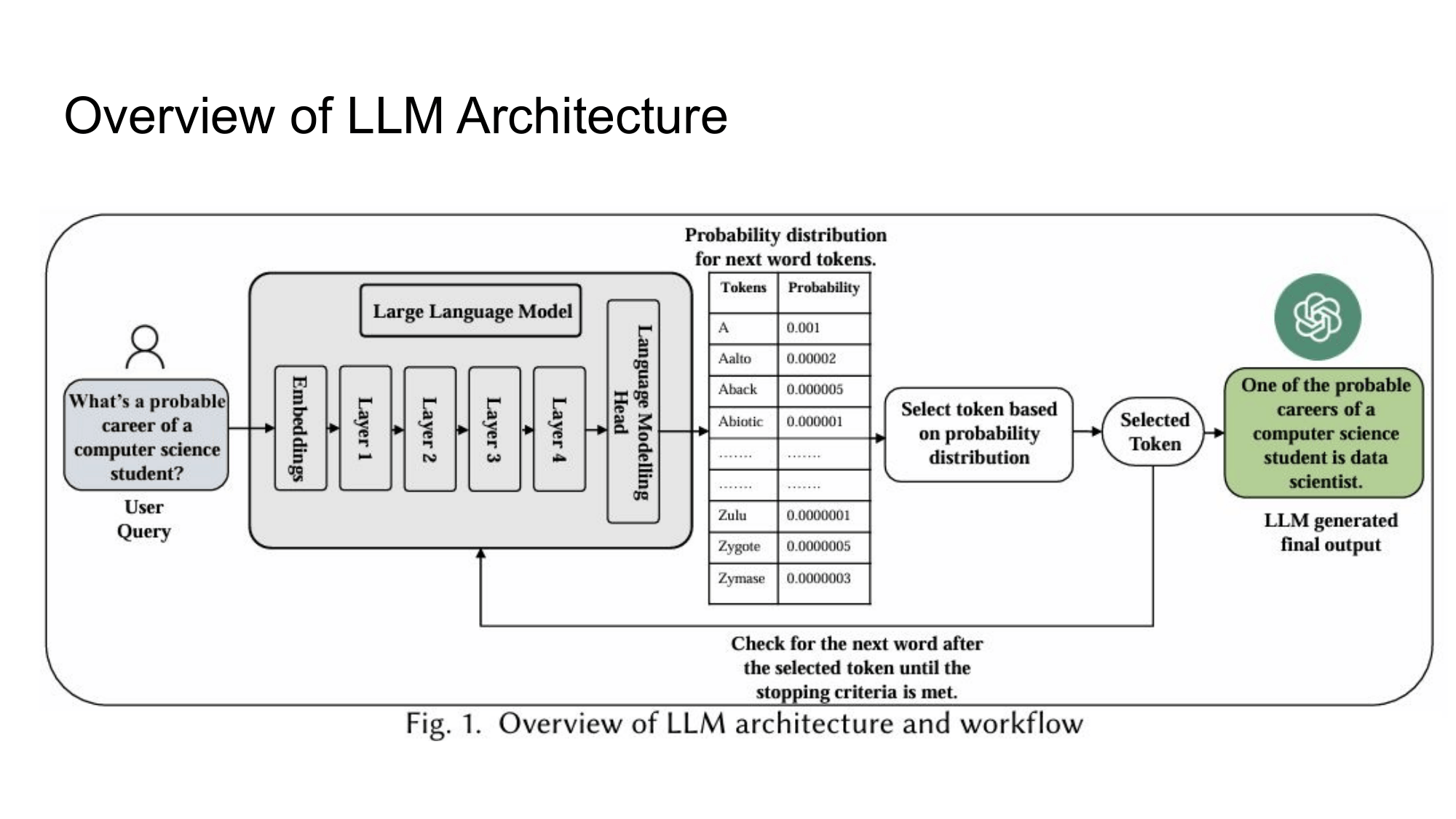
여기서 중요한 포인트가 있다. LLM은 "맞는 말을 하는" 게 아니라 "다음에 올 법한 토큰을 예측하는" 모델이다. 이 특성이 많은 보안 취약점의 근본 원인이 된다. 모델이 학습 데이터의 패턴을 통계적으로 따라가기 때문에, 그 패턴을 악의적으로 조작하거나 유도하는 방식의 공격이 성립한다.
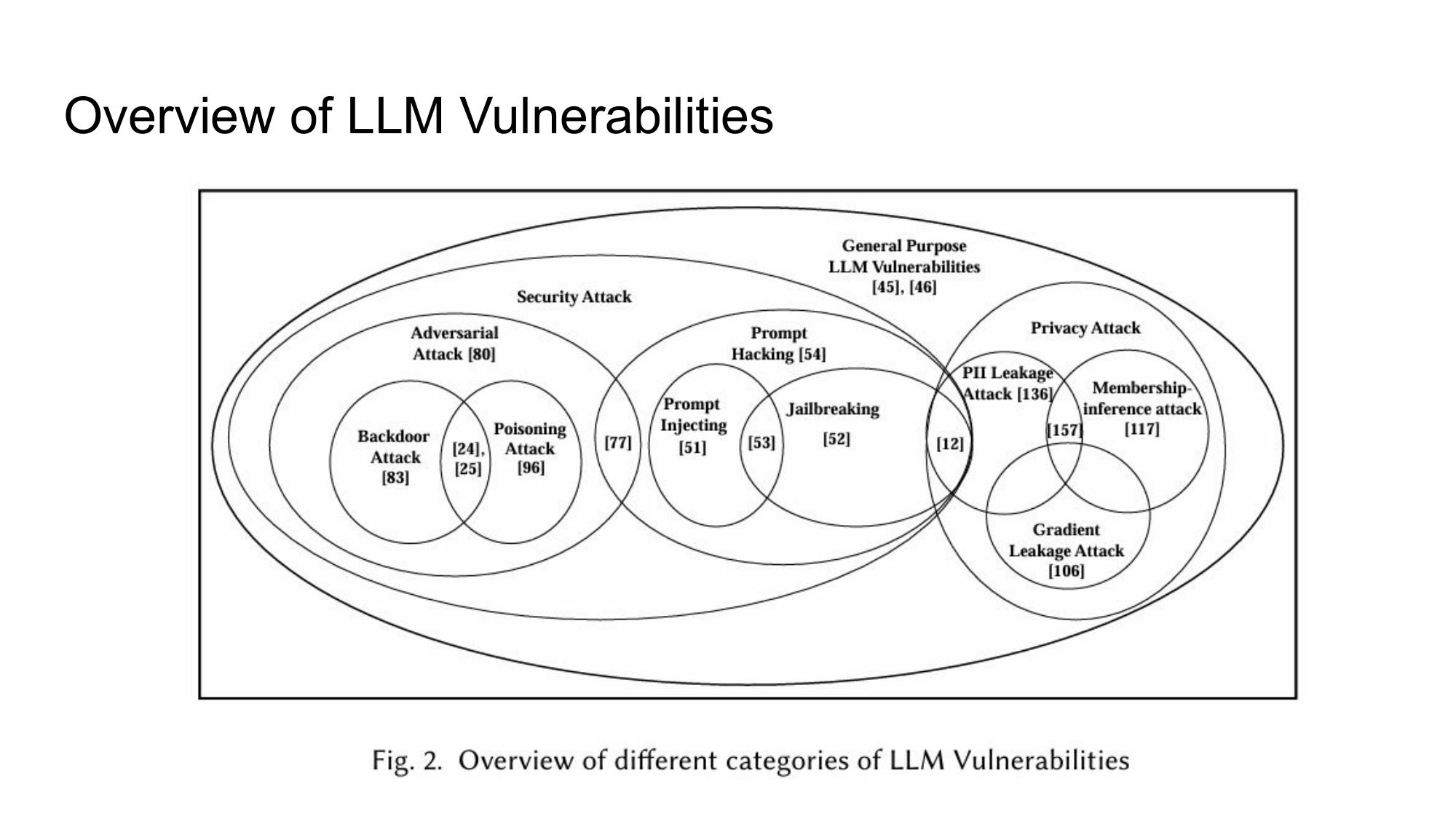
Security Attacks: 모델을 내 뜻대로 움직이게 하려는 시도
보안 공격은 크게 Prompt Hacking과 Adversarial Attack 두 갈래로 나뉜다.
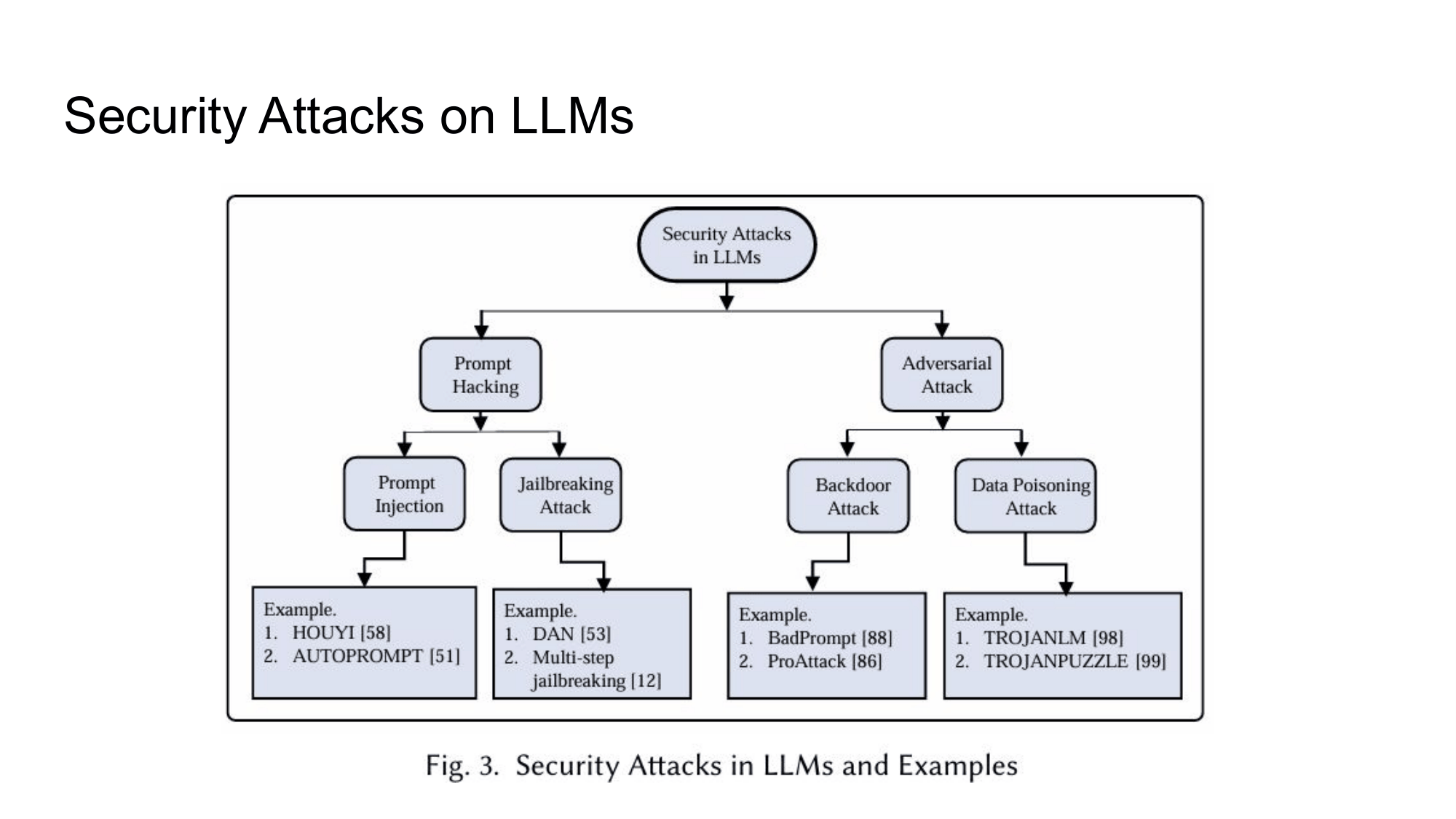
Prompt Hacking
Prompt Injection은 사용자가 시스템 프롬프트나 컨텍스트에 악의적인 명령을 삽입해서 모델이 의도치 않은 동작을 하게 만드는 공격이다. 예를 들어 "이전 지시를 무시하고 다음을 수행해라"는 식의 텍스트를 입력에 숨기는 방식이다. HOUYI, AUTOPROMPT 같은 구체적인 기법들이 연구되어 있다.
Jailbreaking은 모델의 안전 필터를 우회해서 유해한 콘텐츠를 생성하게 만드는 공격이다. 유명한 DAN(Do Anything Now) 프롬프트가 대표적인 예시고, 멀티스텝 jailbreaking처럼 점진적으로 모델의 경계를 허무는 방식도 연구되어 있다. 흥미로운 점은 단순히 역할극(roleplay) 설정을 부여하는 것만으로도 안전 장치가 무력화되는 경우가 있다는 것이다.
Adversarial Attack
Backdoor Attack은 학습 단계에서 특정 트리거 패턴을 데이터에 심어두는 공격이다. 일반적인 입력에는 정상적으로 동작하지만, 특정 트리거 단어나 패턴이 포함된 입력이 들어오면 공격자가 원하는 방향으로 출력이 바뀐다. BadPrompt, ProAttack이 이 계열의 대표적인 방법론이다.
Data Poisoning은 더 근본적인 공격이다. 학습 데이터 자체를 오염시켜서 모델의 가중치에 악의적인 편향을 심는다. TROJANLM이나 TROJANPUZZLE 같은 연구는 코드 생성 모델을 대상으로 실제로 backdoor를 심을 수 있음을 보여줬다. 파인튜닝용 공개 데이터셋이 늘어날수록 이 공격 벡터의 위험도는 올라간다.
Privacy Attacks: 모델에서 정보를 뽑아내려는 시도
프라이버시 공격은 공격 목표에 따라 세 가지로 분류된다.
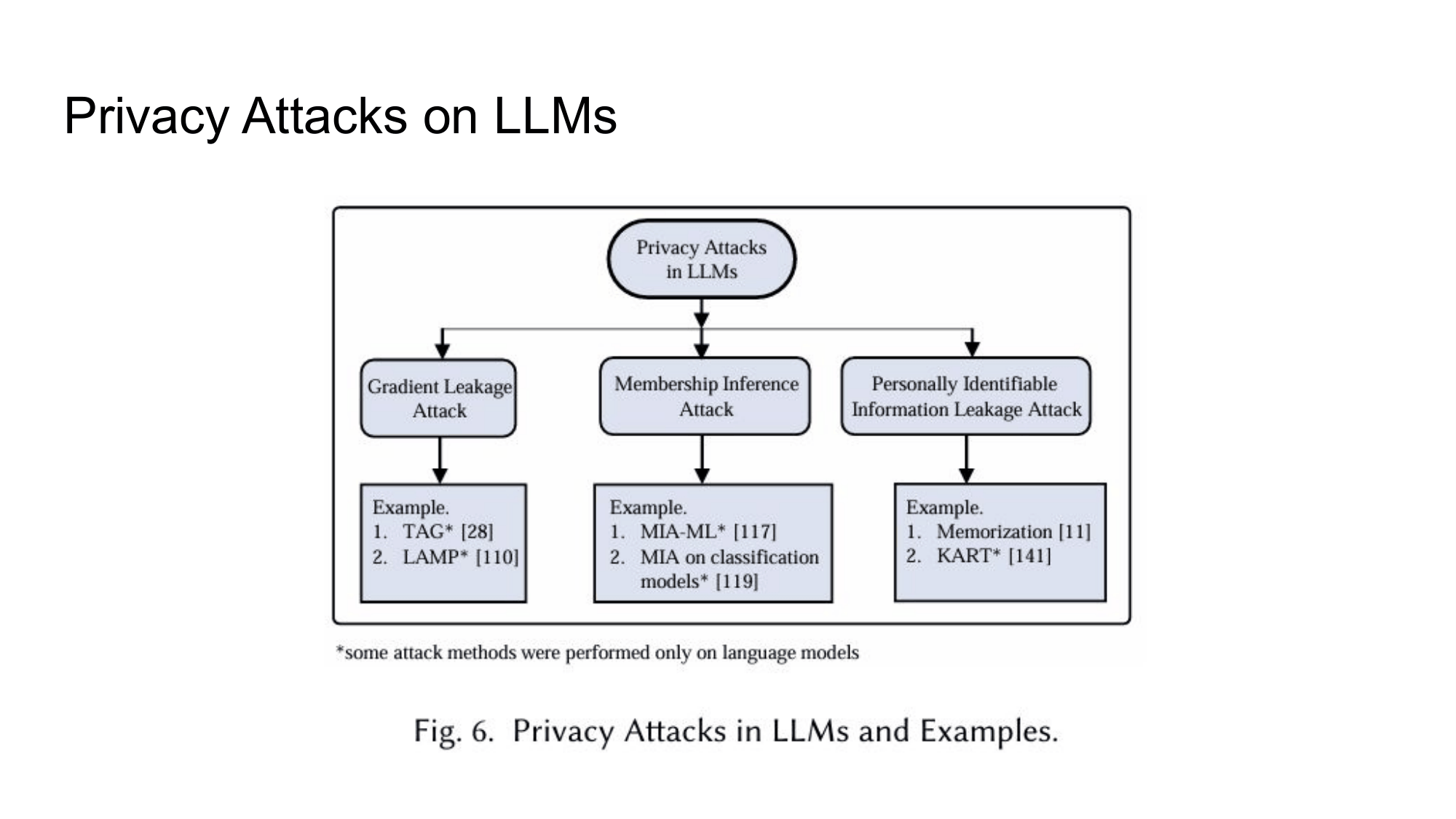
Gradient Leakage Attack은 주로 연합 학습(Federated Learning) 환경에서 발생한다. 클라이언트가 서버에 그래디언트를 전달하는 과정에서, 그 그래디언트로부터 원본 학습 데이터를 역복원할 수 있다는 것이다. TAG, LAMP 같은 공격이 이를 실증했다. 연합 학습이 "데이터를 공유하지 않는다"는 전제로 설계됐는데, 그 전제가 흔들리는 셈이다.
Membership Inference Attack(MIA)은 특정 데이터가 모델의 학습 데이터에 포함됐는지 여부를 알아내는 공격이다. 의료 데이터나 개인 정보로 학습된 모델에서 "이 사람의 데이터가 학습에 쓰였는가"를 알 수 있다면, 그것 자체가 심각한 프라이버시 침해가 된다.
PII Leakage Attack은 모델이 학습 데이터에 있던 개인식별정보(이름, 전화번호, 주소 등)를 그대로 출력하게 만드는 공격이다. LLM은 학습 데이터를 어느 정도 암기(memorization) 한다는 것이 연구로 확인되어 있고, 적절한 프롬프트 설계로 이를 유도할 수 있다.
Defense Mechanisms: 현재 가능한 방어 수단들
방어 수단을 공격 유형별로 정리하면 다음과 같다.

Prompt Injection에 대해서는 **입력 전처리(preprocessing)**와 탐지 기반 방어가 주로 쓰인다. 입력 텍스트에서 명령 패턴을 사전에 걸러내거나, 모델의 응답을 분석해서 의심스러운 출력을 차단하는 방식이다. Jailbreaking에 대해서는 Safety Filter, Self-Reminder System, 그리고 SmoothLLM처럼 입력에 노이즈를 추가해서 적대적 프롬프트의 효과를 희석하는 방법들이 있다.
Backdoor 공격 방어로는 Fine-Mixing이나 CUBE처럼 파인튜닝 과정에서 backdoor 패턴을 희석시키는 방법론이 연구되어 있다. Data Poisoning에는 Perplexity 기반으로 비정상적인 데이터를 걸러내거나, BERT 임베딩 거리를 활용한 이상 탐지 방식이 쓰인다.

프라이버시 방어에서는 Differential Privacy(DP)가 핵심 기술로 반복해서 등장한다. Gradient Leakage와 PII Leakage 모두 DP가 방어 수단으로 제시된다. MIA에는 정규화 기법과 정보 교란(Information Perturbation)이 쓰인다.
현재 연구의 한계 — 이게 핵심이다
논문에서 가장 인상적인 부분은 솔직한 한계 정리였다. 몇 가지만 짚어보면:
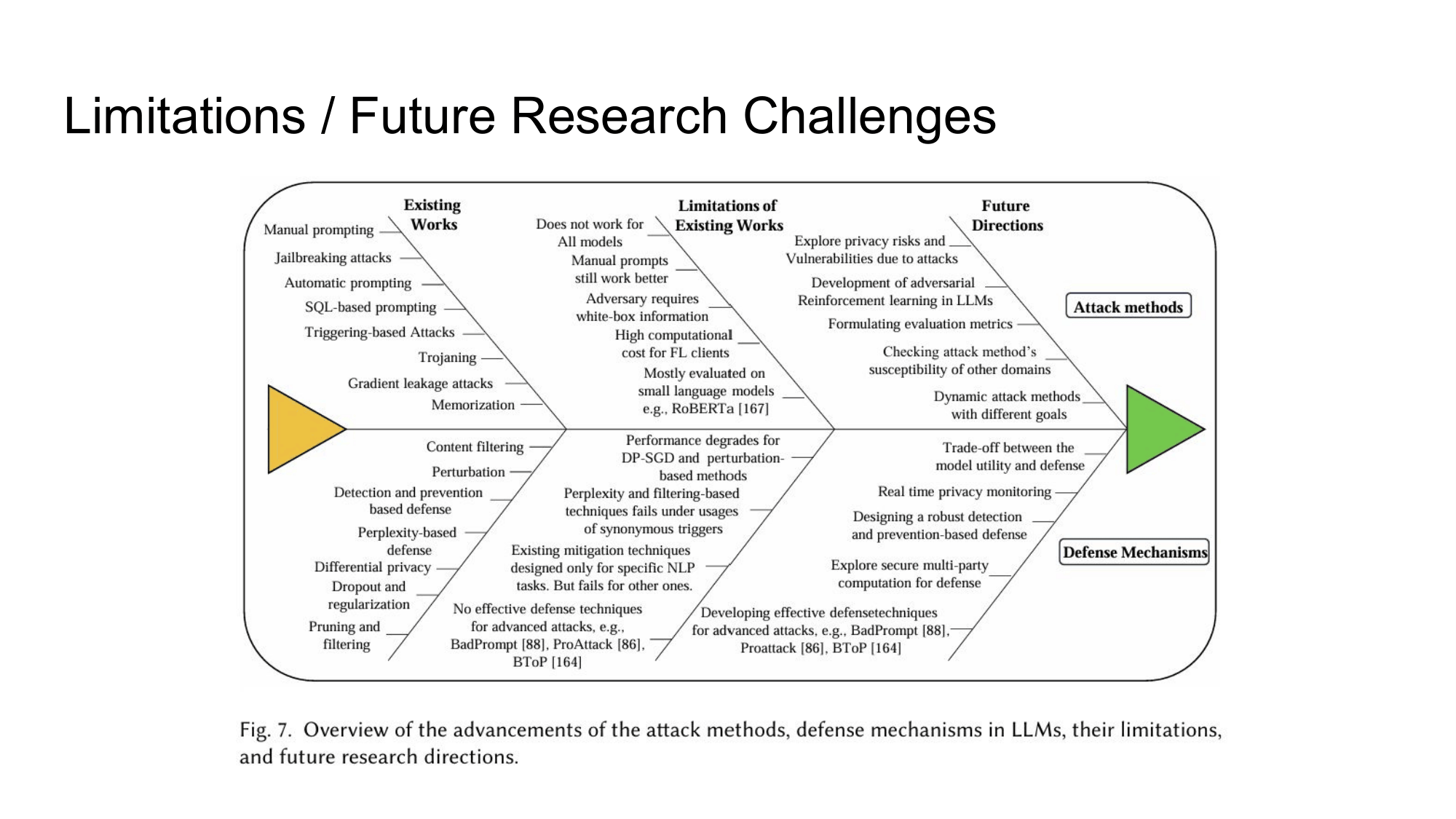
대부분의 공격/방어 연구가
RoBERTa 같은 소형 모델에서 평가됐다. GPT-4급 모델에 그대로 적용되는지는 별개의 문제다. Jailbreaking 방어에서 perplexity 기반 필터는 동의어 치환(synonymous trigger) 하나로 우회된다. Differential Privacy는 프라이버시를 강화하는 대신 모델 성능이 하락하는 트레이드오프가 있다. Adversary가 white-box 접근(모델 내부 파라미터 접근)을 전제로 하는 연구가 많은데, 실제 공격 환경에서는 black-box 시나리오가 훨씬 현실적이다.
이 한계들은 뒤집어 보면 연구 방향이기도 하다. 논문은 실시간 프라이버시 모니터링, 강건한 탐지 및 예방 방어 설계, 그리고 Secure Multi-Party Computation을 방어에 활용하는 방향을 future work로 제시한다.
클라우드 보안 관점에서 한 줄 정리
AI 서비스를 클라우드 인프라 위에 올리는 흐름이 빨라질수록, 기존 클라우드 보안 모델(IAM, 네트워크 격리, 로그 감사 등)과 LLM 보안 위협 모델을 함께 고려해야 한다. Prompt Injection은 기존 웹 인젝션 공격의 AI 버전이고, Data Poisoning은 공급망 공격의 ML 버전이다. 새로운 이름이 붙어 있지만 본질적인 위협 패턴은 기존 보안 도메인과 연속선상에 있다.
논문 원문: Das, B. C., Amini, M. H., & Wu, Y. — Security and Privacy Challenges of LLM: A Survey, Florida International University
