![[Privacy]차분 프라이버시](/content/images/size/w1200/2026/03/----------------4.png)
차분 프라이버시와 라플라스 메커니즘 — 노이즈를 더할수록 안전해진다는 게 무슨 의미인가
차분 프라이버시(Differential Privacy) 수업 실습 기록.
라플라스 메커니즘을 직접 구현하고, epsilon 값에 따라 프라이버시-정확도 트레이드오프가 어떻게 달라지는지 시각화했다.
차분 프라이버시가 왜 필요한가
데이터를 공개하거나 통계 쿼리를 허용할 때, 집계된 결과만 보여주면 개인 정보가 안전하다고 생각하기 쉽다. 그런데 꼭 그렇지 않다. 예를 들어 "A가 포함된 데이터셋의 평균"과 "A가 빠진 데이터셋의 평균"을 비교하면, A의 값을 역산할 수 있다. 이를 차분 공격(differencing attack)이라고 한다.
차분 프라이버시는 이 문제를 수학적으로 해결하려는 프레임워크다. 핵심 아이디어는 단순하다. 쿼리 결과에 의도적으로 노이즈를 추가해서, 특정 개인의 데이터가 포함됐는지 여부를 구분하기 어렵게 만든다. 어떤 개인이 데이터셋에 포함되든 빠지든, 쿼리 결과의 분포가 크게 달라지지 않도록 보장하는 것이다.
이를 수식으로 표현하면, 인접한 두 데이터셋 D와 D'(한 레코드만 차이나는)에 대해 어떤 메커니즘 M이 다음을 만족할 때 ε-차분 프라이버시를 만족한다고 한다.
Pr[M(D) ∈ S] ≤ e^ε × Pr[M(D') ∈ S]ε(epsilon)이 작을수록 두 분포의 차이가 줄어들고, 프라이버시 보호 수준이 높아진다.
라플라스 메커니즘
수치형 쿼리(평균, 합계 등)에 차분 프라이버시를 적용하는 가장 기본적인 방법이 라플라스 메커니즘이다. 쿼리 결과에 라플라스 분포에서 샘플링한 노이즈를 더한다.
M(D) = f(D) + Lap(sensitivity / ε)여기서 **sensitivity(민감도)**는 "데이터셋에서 한 레코드가 바뀔 때 쿼리 결과가 최대 얼마나 달라지는가"를 나타낸다. 노이즈의 스케일은 sensitivity / ε로 결정된다. epsilon이 클수록 노이즈가 작아지고, 결과가 실제 값에 가까워진다.
이번 실습의 파라미터는 다음과 같다.
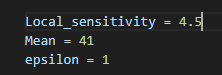
Local_sensitivity = 4.5Mean = 41(실제 값)epsilon = 1(기본값)
python
def laplace_mechanism(true_value, sensitivity, epsilon):
noise = np.random.laplace(0, sensitivity / epsilon)
return true_value + noisesensitivity / epsilon = 4.5 / 1 = 4.5가 라플라스 분포의 스케일 파라미터(b)가 된다.
실험 1: 1000번 쿼리와 95% 신뢰 구간
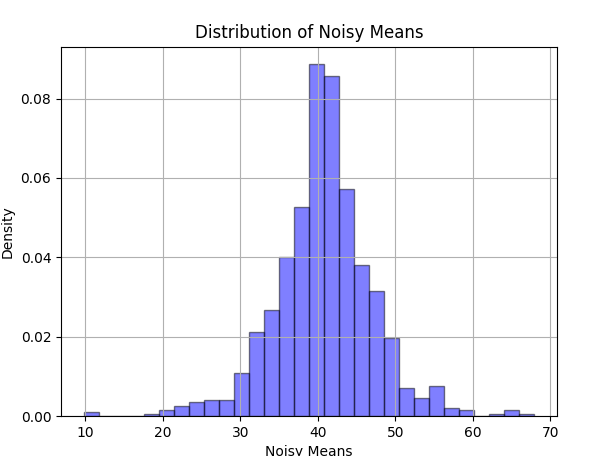
라플라스 메커니즘을 1000번 반복 호출해서 노이즈가 추가된 평균값 분포를 구하고, 각 추정값이 실제 값(41)으로부터 얼마나 떨어져 있는지 시각화했다.
95% 신뢰 구간의 폭은 1.96 × noise_scale로 계산된다. noise_scale = 4.5 / 1 = 4.5이므로, 신뢰 구간 폭은 1.96 × 4.5 ≈ 8.82다. 즉 실제 값 41을 중심으로 ±4.41 범위 안에 추정값이 들어와야 신뢰 구간 내에 포함된다.
그래프에서 파란 점은 신뢰 구간 내에 속한 추정값, 빨간 점은 벗어난 추정값이다. 1000번의 쿼리 중 약 65%(650개)가 신뢰 구간 안에 들어왔다. 쿼리 횟수가 늘어나도 분포의 패턴 자체는 변하지 않는다. 이것이 라플라스 메커니즘의 특성이다. 쿼리를 많이 날린다고 노이즈가 줄어들지 않는다.
실험 2: 데이터셋 비교 (data1 vs data2)
두 데이터셋에 동일한 메커니즘을 적용해서 비교했다.
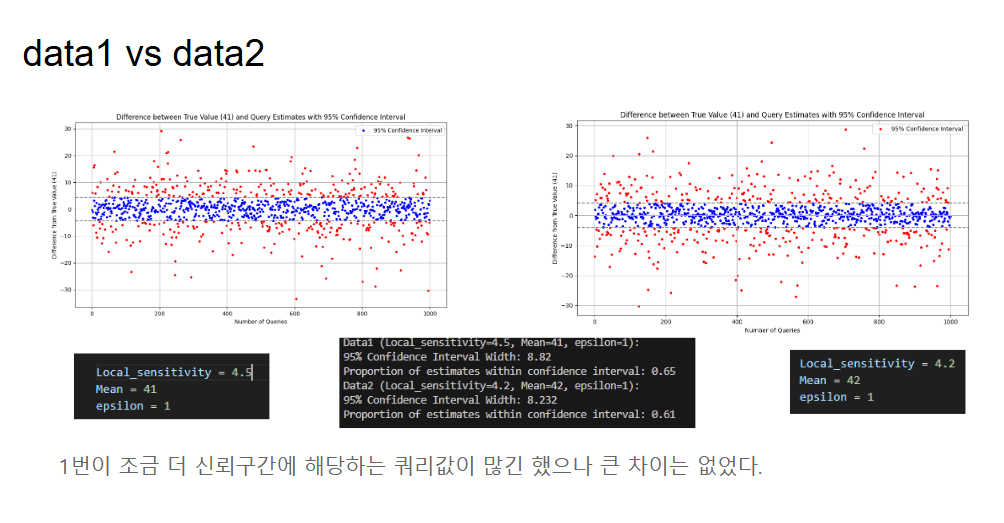
- Data1:
sensitivity=4.5, mean=41, ε=1→ 신뢰 구간 폭 8.82, 신뢰 구간 내 비율 65% - Data2:
sensitivity=4.2, mean=42, ε=1→ 신뢰 구간 폭 8.232, 신뢰 구간 내 비율 61%
Data1이 sensitivity가 약간 높아서 신뢰 구간이 더 넓고, 그 결과 실제 값을 포함하는 비율도 조금 더 높았다. 다만 sensitivity 차이(4.5 vs 4.2)가 크지 않아서 두 결과의 차이도 크지 않았다. 민감도가 비슷하면 epsilon이 같은 이상 프라이버시 보호 수준도 비슷하다는 걸 확인할 수 있었다.
실험 3: epsilon을 2, 3, 4로 높이면?
epsilon 값을 높이면 어떻게 되는지 관찰했다. 결과가 명확했다.
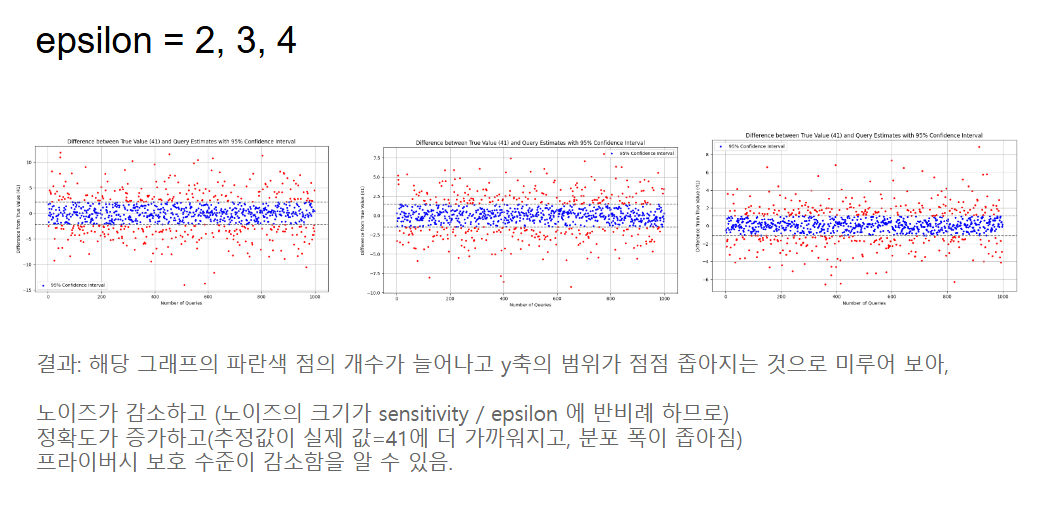
epsilon이 증가할수록 세 가지 변화가 동시에 일어난다. 노이즈 스케일(sensitivity / ε)이 작아지면서 추정값의 분포 폭이 좁아진다. 그래프의 y축 범위가 ε=1일 때 -30~30이었다면, ε=4에서는 -6~8 수준으로 대폭 줄어든다. 파란 점(신뢰 구간 내 포함)의 비율도 늘어난다. 추정값이 실제 값 41에 더 가까워진다는 뜻이다.
그런데 이건 동시에 프라이버시 보호 수준이 낮아진다는 의미기도 하다. 노이즈가 적을수록 공격자가 원본 데이터를 더 정확하게 추론할 수 있다. epsilon이 커질수록 정확도는 올라가고 프라이버시는 내려간다 — 이것이 차분 프라이버시의 본질적인 트레이드오프다.
핵심 인사이트: epsilon은 "프라이버시 예산"이다
실습을 통해 직관적으로 이해한 것은 epsilon을 프라이버시 예산(privacy budget)으로 바라보는 관점이다.
epsilon이 작으면 프라이버시 보호에 "많이 투자"하는 것이고, 그만큼 데이터의 유용성(utility)을 희생한다. epsilon이 크면 정확한 결과를 얻을 수 있지만, 프라이버시 보호가 약해진다. 실제 시스템에서는 허용 가능한 프라이버시 손실 수준을 epsilon으로 먼저 정한 뒤, 그에 맞게 메커니즘을 설계한다.
Apple이 iOS 키보드 사용 통계를 수집할 때, Google이 Chrome 브라우저 데이터를 분석할 때 차분 프라이버시를 적용한다고 알려져 있다. 이때 epsilon 값을 어떻게 설정하느냐가 "개인 정보를 얼마나 보호할 것인가"를 결정하는 핵심 파라미터가 된다.
+추신)
나중에 리뷰하게 된 LLM 보안 논문에서도 Differential Privacy가 Gradient Leakage와 PII Leakage의 방어 수단으로 반복해서 등장했는데, 이 실습 내용을 다시 읽어보고 나니 그 맥락이 더 선명해졌다. LLM 학습 과정에서 그래디언트에 라플라스 노이즈를 추가하면 원본 학습 데이터 복원이 어려워지지만, epsilon을 너무 작게 잡으면 모델 성능이 하락한다. 논문에서 언급한 그 트레이드오프가 정확히 이 실습에서 관찰한 것과 같다.
실습 환경: Python(numpy, matplotlib, pandas), 데이터셋 파라미터: sensitivity=4.5, mean=41, ε=1~4
